Introduction
This text is about automating the interaction with Atlassian Confluence, a commercial product widely used in the corporate world for publishing documentation or other content that needs sharing with a certain team, department or throughout the whole organization. This product is usually integrated with the other Atlassian tools such as Bamboo or JIRA.
By “automating the interaction” I understand document publishing; one may extract data from other components of the system using automated tools and may want this data published in a nice format (if possible). This is indeed possible through the REST interface that Atlassian provides for all its products. The REST functionality does not cover all the features or functions, though, but it’s enough for our scenario. The reference for the Confluence Cloud version can be found here. Please note that the interface may be a bit different between versions, so please check the API reference for your particular Confluence version.
Now that we have the tools and the method, let’s get to the implementation – and obviously, to some code.
I have mentioned before that regular EBS storage in AWS works with a system of credits that are accrued when the volume is idle and are spent when the operation rate requested on the volume grows over the predefined baseline. One can find the detailed explanation in the AWS documentation. This limitation came as an unexpected surprise during the failed project I was part of 18 months back.
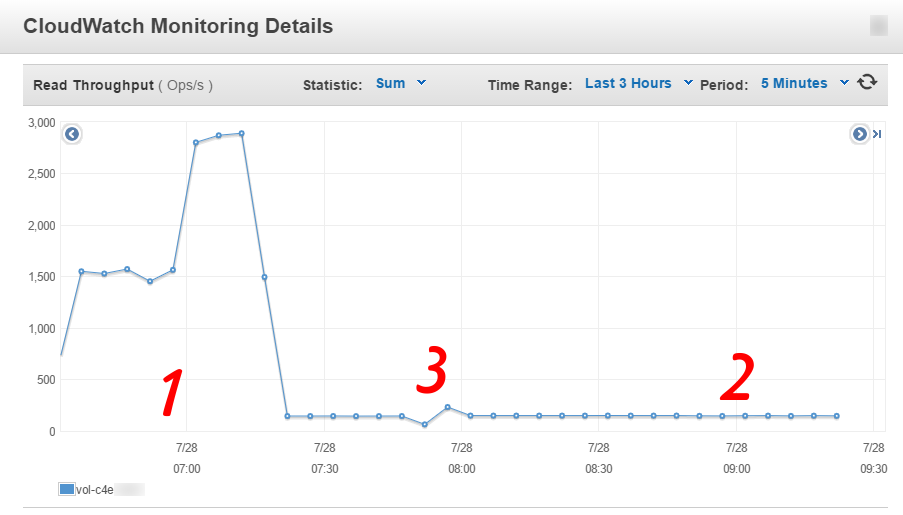
A few days ago while syncing data from a large volume to another, larger volume, I ran into the same problem as well and I decided to capture the state to make things clear for everybody (well, people that are reading this blog).
The CloudWatch read throughput (metric name: VolumeReadOps) graph looked like this during the data sync: