As I was randomly browsing through some site optimization content, I got this suggestion that I should use a “modern” image format such as “webp” to get lower image sizes and implicitly speed up page loading time. I can’t say it made a lot of sense to me that very moment, thus the rabbit hole I have soon found myself going into.
1. Introduction
To sketch out some context, the well-known imge formats such as “jpeg”, “png” or “gif” are with us for 25 years or more; they were put together in a time when both storage and cpu processing power were premiums rather than commodities. That meant accepting compromises and precise product-market fits: “jpeg” became the universal format for everyday pictures, “png” for icons or computer generated images and “gif” was mostly delegated to short animated sequences once the patent covering the corresponding compression algorithm expired in the early 2000s.
AWS provides a complete monitoring engine called CloudWatch. This works with metrics, including custom, user-provided metrics and it’s able to raise alarms when any such metric crosses a certain threshold. This is the only tool used for perfomance monitoring tasks within AWS.
This text will cover a monitoring scenario regarding deploying an arbitrary application to the “Cloud” and then being able to determine what causes performance limiting, be it in the application code itself or coming from limits enforced by Amazon.
Scenario
Let’s assume that you have just started using Amazon Web Services and are deploying applications on this free tier or by using general purpose (T2) instances. You quickly learn that the general purpose instances work with “credits” that allow dealing with short load spikes through performance bursting, but when these credits are exhausted, instance performance is reverted to some baseline. These particular details do not make a lot of sense, but you need to know if the application can meet the desired service targets while sticking to this setup.
When do you need to use some form of Cloud Distribution?
If you consider this concept a form of caching, then you need it when your website passes a certain threshold in terms of users and the volume of data that is being sent out. The actual numeric figure depends entirely on your setup – you may have large files and sending them out of your server may fill up the available bandwidth. Or you may have a lot of users and may want to ease the load on the server by pushing some of this load to somewhere else.
Nevertheless, the purpose of this article is to show you how this is being done by using the AWS CloudFront.
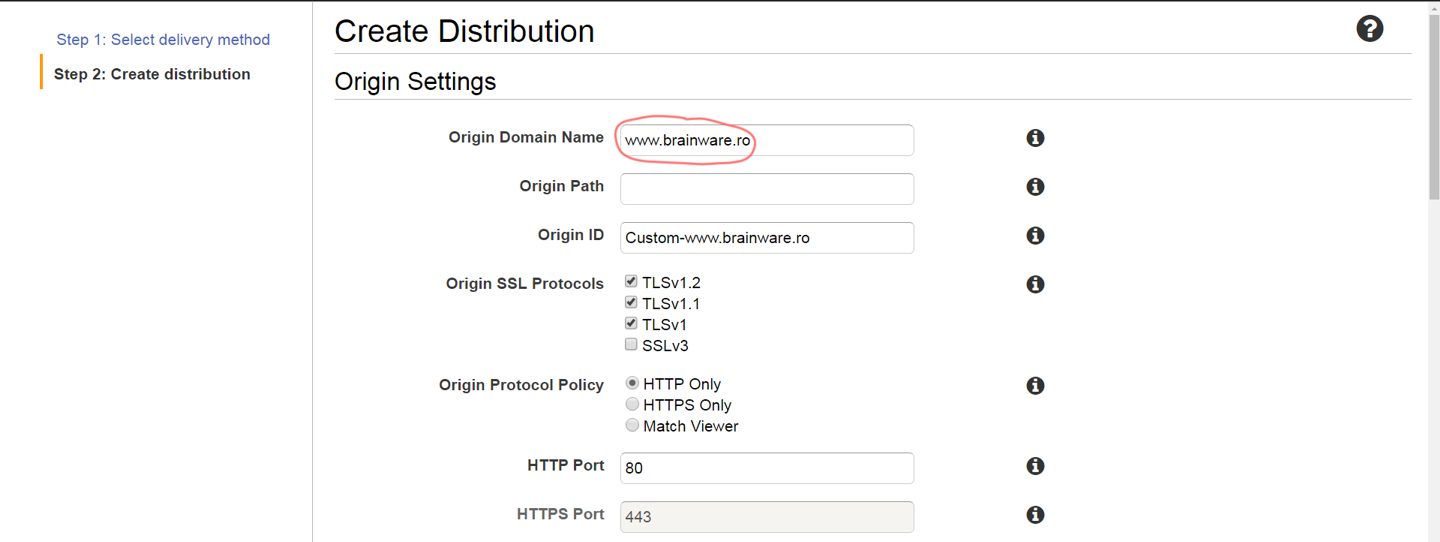
AWS CloudFront
First, you need to go to the “CloudFront” option in the AWS Console and attempt to create a Web distribution. On the creation page you should first fill in your domain name as the distribution origin (the primary source of the content):