When do you need to use some form of Cloud Distribution?
If you consider this concept a form of caching, then you need it when your website passes a certain threshold in terms of users and the volume of data that is being sent out. The actual numeric figure depends entirely on your setup – you may have large files and sending them out of your server may fill up the available bandwidth. Or you may have a lot of users and may want to ease the load on the server by pushing some of this load to somewhere else.
Nevertheless, the purpose of this article is to show you how this is being done by using the AWS CloudFront.
AWS CloudFront
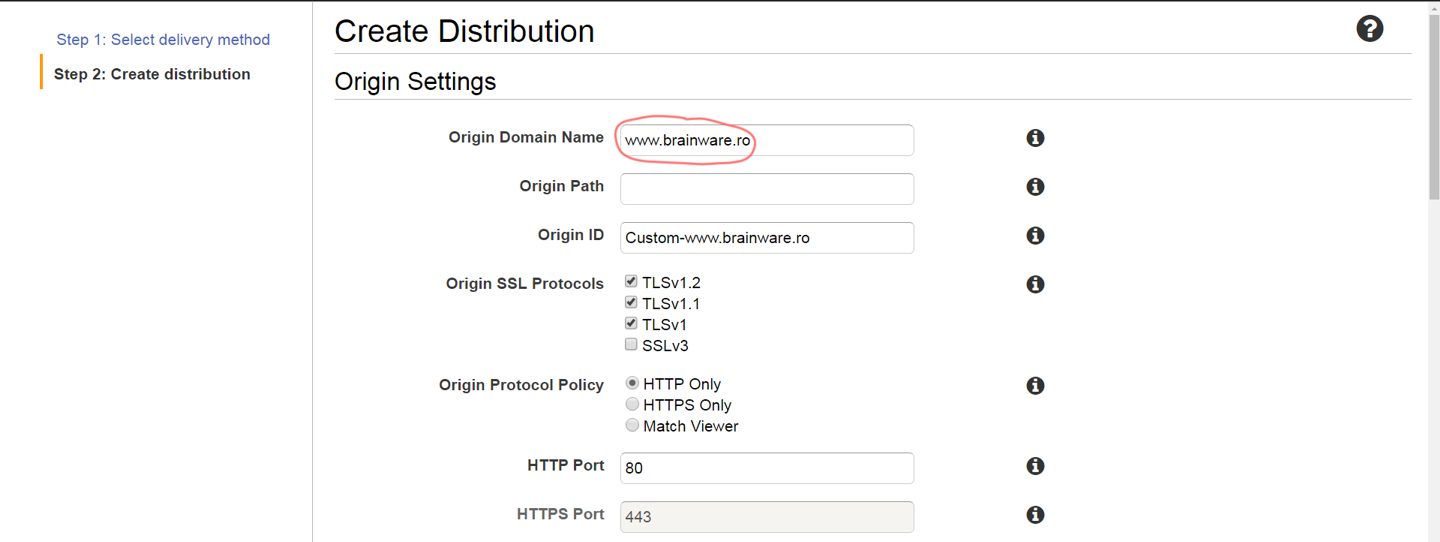
First, you need to go to the “CloudFront” option in the AWS Console and attempt to create a Web distribution. On the creation page you should first fill in your domain name as the distribution origin (the primary source of the content):
About a year ago, during a time when I was barely aware about Cloud Computing or Amazon Web Services, I got assigned, along with a couple of colleagues from this consulting company I was working for, to bring an existing codebase from “alpha” to “production” and then ensure its smooth deployment to Amazon Cloud.
The customer wanted to go “live” in less than 3 months; they also wanted to be able to handle tens of thousands of visitors that would obviously click on banners and make them money. What it’s actually more probable is that they were hoping for a good exit, that is passing the hot potato to somebody else while walking out with a proft. On a side note, there is a term that could be used for these people, but this is not a meme-text so I won’t go more on that route.
{kind=link}
Starting on a new project
With this project, things initially went to some direction: we had to incrementally deal with quite a few functionality issues and in the end we were able to put fixes for more than 100 bugs and glitches. Actually, this was all that we could do, along with the long hours required to get things done.
We could not be bothered by any setup issues with the “Cloud” configuration: we knew near to nothing on the topic and the customer fiercely guarded the “keys to the kingdom”; they would only agree on instance and resource set-ups on a case-by-case basis anyway. They were probably thinking they were paying way too much for those pesky Eastern European contractors (us), so I kind of get the “why” on keeping a close eye over the Amazon bill. It was fine by us; at the end of the day it was their home, with their needs and their rules.
From time to time one may receive a request from QA team in line of:
For testing purposes, I need that /opt/test/xxx directory be limited to 10 Megabytes. This directory is used by this zzz application ran as user tester.
How could the directory size be limited in Linux? Is it even possible? – these are fair questions and the answer is yes. One needs to:
-
Use the directory as a mount point for a size-limited storage device;
-
Use the proper mount options to allow full access to the non-root user specified;
-
Disable Selinux (easy) or allow that particular user to access data on mount points (complicated).
Let’s start with the beginning, the storage device. There are multiple options here:
-
A simple loop device (a regular file used as a file system);
-
A logical volume (LVM), assuming the disk setup is based on this technology and there is enough free space left to accomodate the new device;
-
Attaching a new storage device (e.g. in a Cloud environment like Amazon Web Services).