I’d like to present you the book I am trying to finish reading for some time now; a very dense book, with good practices and interesting details on how to keep planet-wide systems up & running with a bunch of very well prepared people.

What are the lessons one needs to walk away with, from this book? A few bullets:
I have mentioned before that regular EBS storage in AWS works with a system of credits that are accrued when the volume is idle and are spent when the operation rate requested on the volume grows over the predefined baseline. One can find the detailed explanation in the AWS documentation. This limitation came as an unexpected surprise during the failed project I was part of 18 months back.
A few days ago while syncing data from a large volume to another, larger volume, I ran into the same problem as well and I decided to capture the state to make things clear for everybody (well, people that are reading this blog).
The CloudWatch read throughput (metric name: VolumeReadOps) graph looked like this during the data sync:
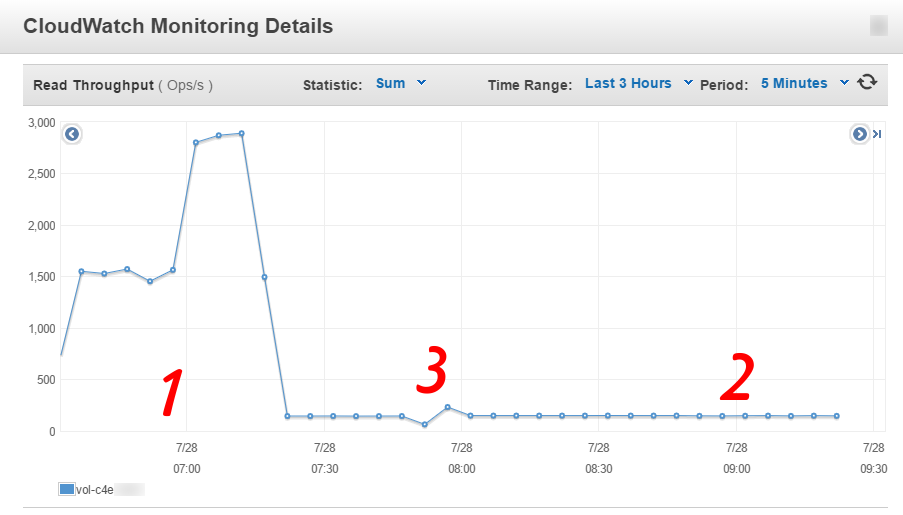
AWS provides a complete monitoring engine called CloudWatch. This works with metrics, including custom, user-provided metrics and it’s able to raise alarms when any such metric crosses a certain threshold. This is the only tool used for perfomance monitoring tasks within AWS.
This text will cover a monitoring scenario regarding deploying an arbitrary application to the “Cloud” and then being able to determine what causes performance limiting, be it in the application code itself or coming from limits enforced by Amazon.
Scenario
Let’s assume that you have just started using Amazon Web Services and are deploying applications on this free tier or by using general purpose (T2) instances. You quickly learn that the general purpose instances work with “credits” that allow dealing with short load spikes through performance bursting, but when these credits are exhausted, instance performance is reverted to some baseline. These particular details do not make a lot of sense, but you need to know if the application can meet the desired service targets while sticking to this setup.